AgentSeal Scanned 1,808 MCP Servers. Two-Thirds Had Findings — and the Worst Class Can't Be Scanned in Isolation.
A May 2026 scan of 1,808 public MCP servers surfaced 8,282 security findings across 16,840 tools. The headline number is that 66% of servers had findings — but the more important result is the toxic-data-flow pattern, a class of risk that no single-server scanner can see.

The largest published security scan of the Model Context Protocol ecosystem to date arrived in May 2026, when AgentSeal released the results of scanning 1,808 publicly accessible MCP servers. The methodology was thorough: connect to each server, enumerate every tool it exposes, and run the tool definitions through a detection pipeline combining regex signatures, deobfuscation, semantic analysis, LLM classification, and — the part that turns out to matter most — a cross-server capability graph.
The headline number is stark. But the most important finding in the report is not a number at all. It is a category of risk that, by its nature, cannot be found by scanning any single server in isolation.
The Headline Numbers
Across the 1,808 servers and 16,840 tools analyzed, AgentSeal recorded 8,282 total security findings:
- 1,196 servers (66%) had at least one security finding.
- 427 critical and 1,841 high-severity findings — 2,268 high-or-critical in total.
Breaking the high-and-critical findings down by category shows where the risk concentrates:
| Category | Count | Share of high/critical |
|---|---|---|
| Code execution | 909 | 40.1% |
| Toxic data flows | 843 | 37.2% |
| Data exposure | 72 | 3.2% |
| Prompt injection | 51 | 2.2% |
| File-system access | 17 | 0.7% |
| Other | 376 | 16.6% |
The dataset also contained several of the named CVEs that defined the 2026 MCP wave: CVE-2025-6514, the CVSS 9.6 remote code execution in mcp-remote; the Cursor “MCPoison” and “CurXecute” bugs (CVE-2025-54136 / CVE-2025-54135); and a Smithery.ai path-traversal flaw that exposed authentication tokens for 3,243 applications.

Code execution leading the table is unsurprising — MCP tools frequently wrap shells, database clients, and file operations, so an injection-prone tool is a direct path to execution. What deserves more attention is the category sitting right behind it, at 37.2% of all high-and-critical findings.
Toxic Data Flows: The Risk You Can’t Scan For
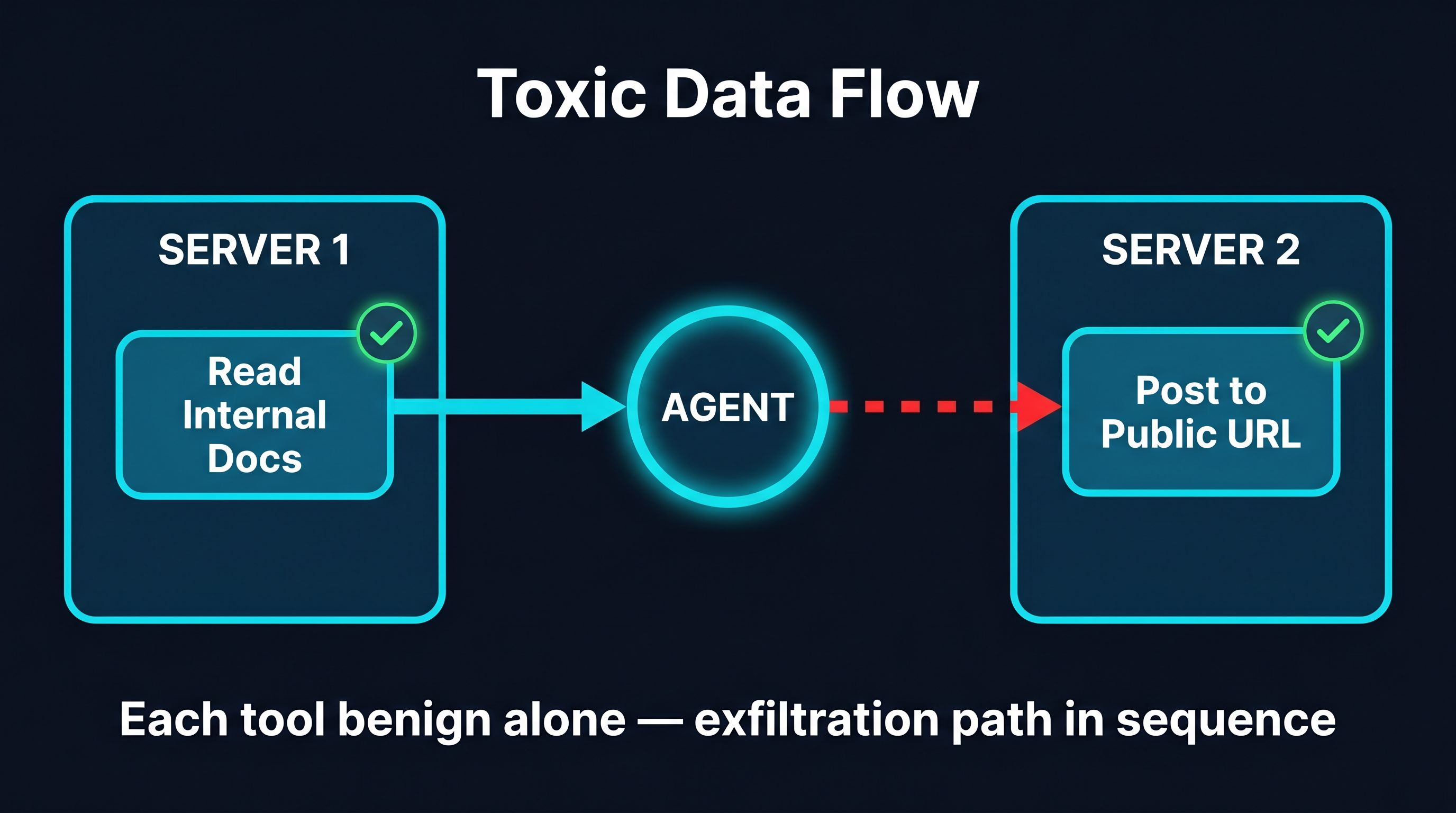
A “toxic data flow,” in AgentSeal’s terminology, is a pair of tools that are each individually benign but that create a dangerous exfiltration path when an agent invokes them in sequence. Neither tool, examined on its own, looks like a vulnerability. The danger lives in the combination.
A concrete shape makes this tangible. Imagine one MCP server that exposes a tool to read internal documents, and another, unrelated server that exposes a tool to post content to a public URL. Each tool is reasonable in isolation. An internal-document reader is useful; an HTTP-post tool is useful. But an agent that calls the first and then feeds its output into the second has just built an exfiltration pipeline out of two “safe” tools — and nothing in either server’s definition would flag it, because the risk does not exist within either server.
In AgentSeal’s broader dataset of 5,125 servers and 53,533 findings, 555 servers participated in toxic data flows. AgentSeal’s own conclusion is the line worth quoting:
Individual tools appear benign, but combinations create exfiltration paths. Gateway solutions require capability mapping across multiple servers rather than isolated tool analysis.
This is the first large-scale empirical quantification of a problem the MCP security community had described only in the abstract. And it has a sharp methodological consequence: a scanner that examines one server at a time is structurally incapable of finding this class. The tool definitions are clean. The vulnerability is a property of the graph of capabilities across servers, not of any node in it.
Why This Changes the Defensive Model
For most of the MCP security discussion in 2025, the implicit defensive model was per-server: scan a server before you trust it, check its tools for injection and over-broad permissions, and approve it if it looks clean. The AgentSeal data shows why that model, while necessary, is insufficient. You can approve two perfectly clean servers and still have created a toxic combination by putting them in the same agent’s reach.
Three implications follow.
Approval has to consider the portfolio, not just the candidate. When you add a server, the relevant question is not only “is this server safe?” but “what new tool sequences does adding this server make possible across everything already approved?” That is a cross-server reasoning step that single-server review skips entirely.
Visibility into invocation sequences is the prerequisite for detection. You cannot detect a read-then-exfiltrate chain unless something is recording that tool A’s call was followed by tool B’s call on a different server. That argues for a layer that observes the full sequence of invocations across servers — which a per-server scanner, by construction, never sees. This is precisely why AgentSeal frames the answer as a gateway problem: a chokepoint that watches all tool calls can map the capability graph that the toxic-flow class lives in.
The full forensic answer spans two layers. A gateway’s invocation log tells you what executed and in what order — which tool on which server returned what, followed by which call. That is necessary but not complete. The remaining question after an exfiltration incident is why the dangerous sequence happened: which task authorized the agent to read the document, what then triggered the follow-up post, and who initiated the workflow that put the two together. That “who ordered the sequence” record lives at the coordination layer — the record of which agent was tasked to do what, by whom — above the individual tool calls. An invocation log shows the dangerous chain ran; the coordination record shows whose instruction caused it. Tracing a toxic flow back to its authorizing intent needs both.
What to Do With This
The practical takeaways from the AgentSeal scan are straightforward, even if the underlying problem is not.
First, treat the 66% figure as a prior, not a panic. The vast majority of public MCP servers carry some finding, which means the safe default for any server you did not write yourself is “untrusted until reviewed,” with an admission step before it can be reached. That is exactly the quarantine-first posture that the 2026 CVE wave already argued for on a different basis.
Second, recognize that single-server scanning has a ceiling. It will catch the code-execution and injection findings that make up the top of the table, and that is genuinely valuable. But 37% of the high-and-critical risk in this dataset — the toxic-flow category — is invisible to it. Closing that gap requires a layer that reasons about combinations: capability mapping at approval time, and invocation-sequence visibility at run time.
Third, invest in the record that lets you answer “why,” not just “what.” When a toxic flow does fire, the gateway log shows you the chain. Reconstructing the authorization behind the chain — the task, the trigger, the initiating agent — is what turns a detected anomaly into an explainable incident. In a single-agent setup that distinction is small. In a multi-agent system, where many agents share a pool of approved tools, it is the difference between a complete post-mortem and a dead end.
AgentSeal’s contribution is to put a number on something the field suspected and to name the class that conventional scanning misses. The 1,808-server scan is a snapshot of an ecosystem that is mostly unreviewed, occasionally exploitable, and — in more than a third of its serious findings — vulnerable in a way that only becomes visible when you look at how tools combine. That last part is the work the next generation of MCP tooling has to do.