chmod for AI Agents: How the MCP Permission Model War Will Shape Agent Security
Three radically different permission models for MCP emerged this month: Unix-style rwxd, DIFC labels, and scope-per-service. The winner will define how enterprises govern AI agent tool access.
The Model Context Protocol has a permissions problem. Not a vulnerability, not a CVE — a design gap. MCP defines how AI agents discover and invoke tools on remote servers, but it says almost nothing about who gets to invoke what, under which conditions, and with what constraints. The spec delegates authorization to the transport layer and the server implementation, which in practice means every deployment invents its own access control scheme.
This month, three independent projects proposed radically different answers. Wombat introduced Unix-style rwxd permission bits for MCP tools. GitHub’s gh-aw-mcpg applied Decentralized Information Flow Control labels from academic security research. ScopeGate took the OAuth scope-per-service approach familiar to API developers. And a fourth paradigm — quarantine plus container isolation — has been operating in production for months through projects like MCPProxy.
Each model makes different assumptions about what matters most: simplicity, formal security guarantees, developer ergonomics, or operational safety. The one that gains adoption will define how enterprises govern AI agent tool access for years to come. This post examines all four approaches on their merits.
The Permission Gap in MCP Today
Before comparing solutions, it is worth understanding what MCP currently provides. The MCP specification defines a tools/list endpoint that returns available tools with their schemas, and a tools/call endpoint that invokes them. Authentication is handled at the transport level — typically OAuth 2.1 bearer tokens over HTTP or implicit trust over stdio connections. Once authenticated, a client can call any tool the server exposes.
This is roughly equivalent to giving every authenticated user root access to every command on a Unix system. It works for single-user development environments. It does not work when an enterprise has hundreds of agents connecting to dozens of MCP servers, each exposing tools with different risk profiles — some read data from a CRM, others execute database queries, others deploy infrastructure.
The MCP specification’s tool annotations added metadata hints like readOnlyHint and destructiveHint in the March 2025 revision, but these are advisory. Nothing in the protocol enforces them. A malicious or misconfigured agent can ignore annotations entirely. The gap between “this tool is marked as destructive” and “this agent is not allowed to call destructive tools” is the space where all four permission models operate.
Wombat: Unix-Style rwxd Permissions
The Wombat project takes the most immediately intuitive approach: apply the Unix permission model to MCP tools. Just as files in Unix have read, write, and execute bits for owner, group, and others, Wombat assigns permission bits to each tool for each agent identity.
The permission model extends the classic rwx triplet with a d bit for “destructive” operations:
- r (read): The agent can discover the tool and read its schema
- w (write): The agent can invoke the tool with parameters that modify state
- x (execute): The agent can invoke the tool for read-only operations
- d (destructive): The agent can invoke the tool for operations that delete or irreversibly modify resources
A tool like database_query might be configured as r-x- for analyst agents (can discover and execute read-only queries) and rwxd for admin agents (full access including destructive operations). The permission string looks familiar to anyone who has typed ls -la in a terminal, which is precisely the point.
Strengths. The Unix model has fifty years of proven usability. System administrators understand it immediately. The learning curve is essentially zero for any team that manages Linux servers. Permission bits are compact, fast to check, and trivial to store — a single byte per tool-agent pair covers the entire permission space. Wombat’s implementation adds negligible latency to tool invocations because the permission check is a bitmask operation.
The model also maps cleanly to MCP’s existing tool annotations. The readOnlyHint annotation corresponds to whether the w and d bits are relevant. The destructiveHint maps directly to the d bit. Wombat can ingest annotations as defaults and let administrators override them, creating a smooth migration path from the current advisory system to enforced permissions.
Weaknesses. The Unix model was designed for a filesystem with a tree-shaped namespace. MCP tool access patterns are not tree-shaped. An agent might need read access to database_query but only for specific tables, or write access to email_send but only to internal addresses. The rwxd bits operate at the tool level — they cannot express constraints on parameters within a tool invocation.
The model also lacks any concept of information flow. Granting an agent rx on both read_customer_data and post_to_slack does not capture the policy “customer data must not flow to Slack.” Each permission is evaluated independently. Composing tools into workflows that preserve security invariants requires external policy logic that the permission bits cannot express.
GitHub gh-aw-mcpg: DIFC Secrecy and Integrity Labels
GitHub’s gh-aw-mcpg project applies Decentralized Information Flow Control, a formal model from academic security research, to MCP tool access. DIFC tracks how data flows between components and prevents unauthorized information leakage by construction.
In DIFC, every piece of data carries two labels: a secrecy label that restricts who can read it, and an integrity label that restricts who can modify it. When an agent reads data from a tool, the data’s secrecy label propagates to the agent’s state. The agent can then only write to tools whose secrecy labels are at least as restrictive — preventing downward flows from high-secrecy sources to low-secrecy destinations.
For example, a tool read_medical_records might carry secrecy label {HIPAA, patient-data}. An agent that invokes this tool inherits these labels. If it then attempts to call post_to_public_api with secrecy label {} (no restrictions), the DIFC runtime blocks the invocation because data would flow from a more restrictive context to a less restrictive one.
Strengths. DIFC solves the information flow problem that Unix-style permissions fundamentally cannot express. In enterprises where regulatory compliance requires demonstrable data isolation — healthcare, financial services, government — DIFC labels provide a mathematically provable guarantee that sensitive data does not leak through tool composition. This is not a heuristic or a best-effort policy; it is an invariant enforced by the runtime.
The integrity labels address a second problem: tool poisoning. If a tool’s outputs carry a low integrity label (because the tool fetches data from untrusted sources), agents cannot use those outputs as inputs to high-integrity tools (like deployment pipelines) without explicit declassification. This creates a formal defense against prompt injection attacks that attempt to influence downstream tool calls through compromised data sources.
Weaknesses. DIFC is notoriously difficult to operationalize. Label management becomes complex quickly — an enterprise with fifty data classifications and twenty tool servers produces a label space that humans struggle to reason about. The academic literature on DIFC acknowledges this: systems like Flume and Laminar achieved formal elegance but saw limited production adoption because the operational overhead exceeded what most engineering teams could absorb.
The gh-aw-mcpg implementation requires agents to be DIFC-aware. Every tool invocation must propagate labels correctly through the agent’s internal state. For agents built on language models, where the “state” is a context window managed by inference code, implementing correct label propagation is a significant engineering challenge. A single mislabeled context element can either block legitimate operations (over-labeling) or permit unauthorized flows (under-labeling).
The model also introduces latency. Every tool call requires a label comparison operation, and label sets grow as agents interact with more tools in a session. While the computational cost of individual comparisons is low, the accumulated overhead in long-running agent sessions with many tool invocations is measurable.
ScopeGate: Scope-Per-Service Authorization
ScopeGate takes the most pragmatic approach: extend OAuth 2.0 scopes to MCP tool authorization. Every MCP server defines a set of scopes, and agent tokens are issued with specific scope grants. When an agent invokes a tool, the server checks whether the agent’s token includes the required scope.
This maps directly to how API authorization works across the industry today. A scope like crm:contacts:read grants read access to contact tools on the CRM MCP server. database:query:execute grants query execution on the database server. Scopes are hierarchical — crm:* grants all CRM operations — and can include parameter constraints encoded in the scope string itself.
Strengths. ScopeGate leverages existing infrastructure. Any organization running OAuth 2.0 or OIDC already has the token issuance, scope management, and audit logging infrastructure that ScopeGate requires. The integration point is the MCP server’s token validation middleware, which is typically a few dozen lines of code. There are no new concepts to learn, no new infrastructure to deploy, and no changes to the agent runtime.
The scope model naturally supports multi-tenancy. Different agent identities receive different scope sets from the authorization server, and the MCP server enforces them without needing to know about the organizational structure behind the tokens. This is the same model that allows Google Workspace to offer different API scopes to different third-party applications — proven at massive scale.
Parameter-level constraints are also possible within the scope model. A scope like database:query:execute:tables=public.* restricts query execution to public-schema tables. While the constraint language is limited compared to a full policy engine, it covers the most common use cases without adding complexity.
Weaknesses. Scopes are static. They are baked into tokens at issuance time and cannot adapt to runtime context. An agent that legitimately needs elevated permissions for a specific workflow must obtain a new token with broader scopes, which creates an incentive to request the broadest possible scopes upfront — the same “scope creep” problem that plagues OAuth in traditional API ecosystems.
The model also does not address information flow between tools on different servers. An agent with crm:contacts:read and slack:messages:write can read customer contacts and post them to Slack without any constraint. ScopeGate governs access to individual tools but not the composition of tool invocations across a session. For enterprises that need to enforce data flow policies, scopes alone are insufficient.
Scope strings also lack standardization across MCP servers. Without a common taxonomy, every server defines its own scope hierarchy, and administrators must maintain mappings between organizational policies and per-server scope vocabularies. This is manageable for five MCP servers. It becomes a governance challenge at fifty.
Quarantine and Container Isolation: The Runtime Safety Net
A fourth paradigm sidesteps the permission model question entirely by focusing on containment rather than access control. Projects like MCPProxy run each MCP server connection inside a Docker container with restricted network access, filesystem isolation, and resource limits. Rather than deciding whether an agent should be allowed to invoke a tool, this approach ensures that even if a tool invocation does something unexpected, the blast radius is contained.
MCPProxy implements this through a quarantine system: new or untrusted MCP servers are placed in quarantine mode where their tools are discoverable but all invocations are held for human approval. Once a server demonstrates trustworthy behavior, it can be promoted to automatic execution within its container sandbox. The approach combines BM25-based tool discovery across multiple servers with per-server isolation boundaries.
Strengths. Container isolation provides defense in depth regardless of the permission model in use. Even if an access control check is misconfigured, the container boundary limits what a compromised tool can reach. This is particularly valuable for MCP servers that execute arbitrary code — filesystem tools, shell commands, database clients — where the range of possible actions is too broad to capture in any permission schema.
The quarantine-then-promote workflow matches how security teams actually evaluate new services in enterprise environments. Rather than requiring upfront permission configuration (which assumes administrators understand every tool’s behavior before deployment), it allows observation-based trust building. This reduces the risk of both over-permissioning (granting access to tools that turn out to be dangerous) and under-permissioning (blocking tools that turn out to be safe).
The approach also composes with any of the three permission models described above. Running DIFC label enforcement inside a container, or checking scopes before forwarding to a containerized server, adds layers of defense without conflict.
Weaknesses. Container isolation is an operational model, not a permission model. It does not help an administrator answer the question “which agents should be able to call which tools” — it only limits the damage when that question is answered incorrectly. Organizations still need a permission layer; container isolation supplements but does not replace one.
The performance overhead is non-trivial. Each MCP server connection running in its own container consumes memory and adds network latency for every tool invocation. For high-throughput deployments with hundreds of concurrent agent sessions, the resource cost of per-connection isolation may be prohibitive.
Quarantine also introduces operational friction. In fast-moving environments where new MCP servers are deployed frequently, the quarantine approval workflow can become a bottleneck. Automated promotion policies based on behavioral analysis can mitigate this, but they introduce their own complexity.
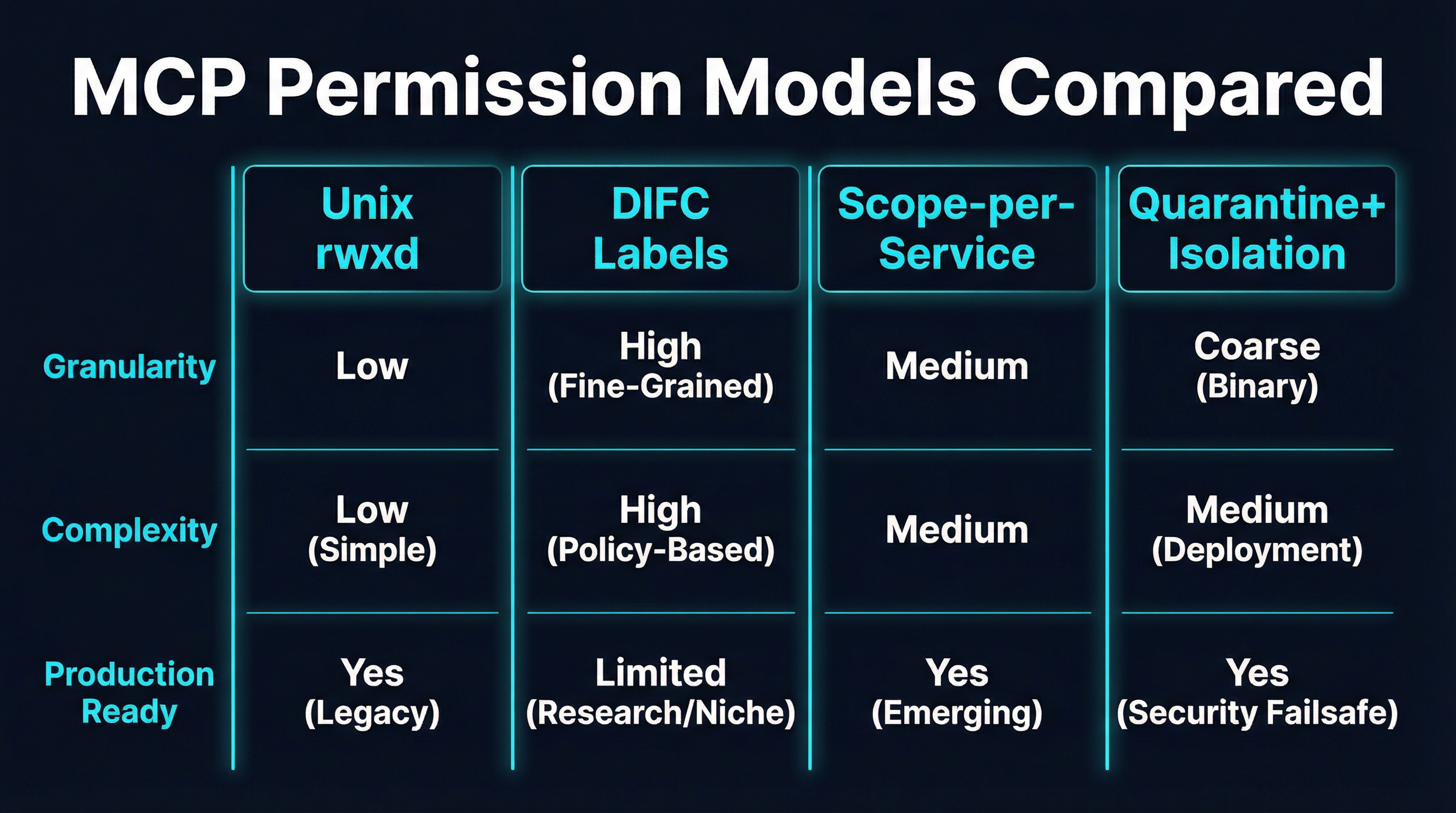
Comparing the Approaches
The four models optimize for different properties, and the right choice depends on which properties an organization values most.
| Property | Unix rwxd | DIFC Labels | Scope-per-Service | Quarantine + Isolation |
|---|---|---|---|---|
| Learning curve | Very low | Very high | Low | Medium |
| Granularity | Tool-level | Data-flow-level | Tool + parameter | Server-level |
| Information flow control | No | Yes (formal) | No | No |
| Infrastructure requirements | Minimal | DIFC-aware runtime | OAuth 2.0 / OIDC | Docker / container runtime |
| Multi-tenancy support | Limited | Strong | Strong | Strong |
| Performance overhead | Negligible | Moderate | Low | Moderate-to-high |
| Composability | Low | High | Medium | High (additive) |
| Production maturity | Early | Research | Proven (in OAuth) | Available today |
For a development team building internal tools with a small number of agents, Wombat’s Unix-style permissions provide adequate control with minimal overhead. For a healthcare or financial services company with strict data flow requirements, DIFC labels offer guarantees that no other model can match — if the team can absorb the implementation complexity. For organizations already running OAuth infrastructure that want incremental security improvement, ScopeGate is the path of least resistance. And for any deployment where the consequences of tool misuse are severe enough to justify runtime containment, container isolation provides a safety net that complements whatever permission model sits on top.
Where This Is Heading
The MCP permission space is likely to converge rather than fragment. The history of access control systems shows a consistent pattern: simple models get adopted first, and formal models influence the design of the simpler ones over time. POSIX ACLs borrowed concepts from capability systems. OAuth scopes absorbed ideas from XACML policy languages. The same pattern will likely play out here.
The most probable near-term outcome is that MCP servers adopt scope-based authorization (because the OAuth infrastructure already exists) while gateways and proxies enforce additional constraints at the network level (because defense in depth is a non-negotiable enterprise requirement). DIFC concepts will likely influence how scope taxonomies are designed — particularly around data classification labels that prevent cross-category flows — without requiring full DIFC runtime adoption. And Unix-style permission bits may find a niche in local development environments and single-tenant deployments where simplicity outweighs expressiveness.
What matters more than which model wins is that the MCP ecosystem converges on something. The current state — where every deployment invents its own authorization scheme or, more commonly, has no authorization scheme at all — is the real security risk. Any of these four approaches, competently implemented, is a dramatic improvement over the status quo.
The chmod moment for AI agents is arriving. The only question is whether the ecosystem will standardize before the first major breach forces it to.