From Theory to Exploit: Real MCP Attacks and How Gateways Stop Them
MCP security has moved from theoretical risks to documented exploits. ContextCrush, Unit42 sampling attacks, and cross-agent escalation prove the attack surface is real. Here is how gateway-level interception stops them.

For most of 2025, MCP security discussions were speculative. Researchers described theoretical attack vectors — tool poisoning, schema drift, prompt injection through tool descriptions — and the community debated how likely they were in practice. That debate is over. In the first quarter of 2026, multiple research teams independently demonstrated working exploits that compromise real MCP infrastructure, exfiltrate secrets, and hijack agent sessions. The attack surface is not theoretical. It is documented, reproducible, and actively being probed in the wild.
This post breaks down the three major exploit categories that emerged in early 2026, explains why conventional defenses fail against them, and examines how gateway-level interception — an architectural pattern gaining traction across the ecosystem — addresses each one.
ContextCrush: When a Top-10 MCP Server Becomes a Weapon
The most alarming disclosure came from Noma Security in February 2026. Their research team demonstrated that Context7, one of the most popular MCP servers in the ecosystem with roughly 50,000 GitHub stars and over 8 million npm downloads, could be weaponized to deliver malicious instructions directly into developer IDE sessions.
The attack exploited Context7’s “Custom Rules” feature, which allowed library maintainers to set AI instructions that would be served alongside documentation. The researchers registered a library, uploaded malicious rules, and then used self-interaction to generate fake engagement metrics — earning a trending badge and top 4% ranking on the platform. When a developer queried documentation for this library, Context7’s MCP server delivered the poisoned rules directly into the AI agent’s context, indistinguishable from legitimate instructions.
The payload was devastating. The researchers demonstrated exfiltration of .env files (containing API keys and secrets) by having the agent create GitHub Issues on an attacker-controlled repository with the file contents embedded. A secondary payload deleted local project directories under the guise of a “cleanup” operation.
What makes ContextCrush particularly significant is the trust chain it exploits. Context7 was not a rogue MCP server — it was a legitimate, widely-used tool that developers had explicitly chosen to install. The malicious content was delivered through the platform’s own infrastructure. As Noma’s report put it: “The attacker plants malicious custom rules in Context7’s registry, and Context7’s infrastructure delivers them through the MCP server to the AI agent running in the developer’s IDE.”
The vulnerability was patched within five days of disclosure. But the pattern it revealed — that any MCP server with user-contributed content is a potential delivery vector for context poisoning — applies broadly across the ecosystem.
Unit42’s Sampling Attacks: Three Vectors, One Protocol Feature
Palo Alto Networks’ Unit42 team took a different angle, focusing on MCP’s sampling feature — the mechanism that allows servers to request LLM completions through the client. Their research identified three distinct attack vectors, all exploiting the same protocol capability.

Resource theft through hidden token consumption. A malicious MCP server appends covert instructions to legitimate prompts sent through the sampling interface. While the client displays only the requested output (say, a code summary), the LLM silently processes additional hidden prompts — generating content, executing reasoning chains, or performing computations that consume API credits without the user’s knowledge. The visible output looks normal. The bill does not.
Conversation hijacking through persistent injection. Servers embed behavioral directives in LLM responses that persist across conversation turns. Unlike a one-shot injection, this approach modifies the assistant’s behavior for the entire session. The injected instructions become part of the conversation context, meaning every subsequent interaction is influenced by the attacker’s payload. The user sees normal responses but cannot detect that the agent’s decision-making has been fundamentally altered.
Covert tool invocation. The most dangerous of the three. Servers inject prompts that cause the LLM to invoke other tools — file system operations, network requests, code execution — without explicit user consent. The acknowledgments are buried within normal output, making them nearly invisible during regular use. This effectively gives a malicious MCP server the ability to trigger actions through any other tool the agent has access to, turning a single compromised server into a pivot point for the entire agent’s capability set.
The common thread across all three vectors is that the attacks originate from within the MCP protocol’s own communication channels. They do not require network-level exploits, credential theft, or social engineering beyond the initial server connection. The protocol’s trust model — where servers are assumed to be cooperative participants — becomes the vulnerability itself.
The Trust Exploit Spectrum: Identity, Delegation, and Tenancy
Security Boulevard’s analysis and the OWASP MCP Top 10 project together paint a broader picture that extends beyond individual exploits to systemic architectural weaknesses.
Context injection (OWASP MCP06 — Intent Flow Subversion) is the umbrella category that ContextCrush falls under. Any content that enters the agent’s context assembly pipeline — tool descriptions, retrieved documents, server responses — becomes part of the decision-making substrate. Without upstream validation, injected directives override policy constraints. The Security Boulevard analysis notes: “If malicious, manipulated, or unauthorized content enters the context assembly pipeline, it becomes part of the decision-making substrate.”
Delegation exploitation targets the handoff between agents and tools. When an MCP server embeds delegation metadata in its payloads — claims about what permissions it has been granted, what actions it is authorized to perform — agents that treat these claims as authoritative without independent verification are vulnerable to privilege escalation. OWASP MCP02 (Privilege Escalation via Scope Creep) formalizes this: loosely defined permissions expand over time, and attackers exploit weak scope enforcement to perform actions far beyond what was originally authorized.
Cross-tenant context leakage is the enterprise-specific nightmare. In multi-tenant deployments where multiple organizations share MCP infrastructure, context assembly that retrieves from shared memory without tenant enforcement can leak data across organizational boundaries. This is not merely a security failure — as Security Boulevard puts it, “it is a regulatory liability” with implications under GDPR, HIPAA, and SOC 2 compliance frameworks.
Token mismanagement (OWASP MCP01) rounds out the picture. Hard-coded credentials, long-lived tokens, and secrets stored in model memory or protocol logs create persistent access vectors. The Gravitee survey found that 45.6% of organizations still depend on shared API keys for agent-to-agent authentication, meaning that compromising a single agent’s credentials gives an attacker access to every service that agent can reach.
Why Traditional Defenses Fail
The instinct for most security teams is to apply familiar patterns: input validation, WAF rules, network segmentation, rate limiting. These are necessary but insufficient against MCP-specific attacks for a fundamental reason: the malicious content arrives through trusted channels.
ContextCrush did not exploit a buffer overflow or SQL injection. It delivered carefully crafted natural language instructions through a legitimate MCP server’s documented API. The content passed through every layer of the stack exactly as designed. Input validation cannot catch it because the “input” is indistinguishable from legitimate MCP server responses. Network segmentation cannot prevent it because the traffic flows over established, authorized connections.
Unit42’s sampling attacks are even harder to detect with traditional tools. The malicious prompts are embedded in protocol-level communication between server and client. They do not trigger WAF signatures because they are not HTTP exploits — they are semantic exploits that manipulate the LLM’s behavior through its own reasoning process.
This is why the security community has converged on a different architectural pattern: gateway-level interception.
Gateway-Level Interception: Inspecting What Firewalls Cannot See
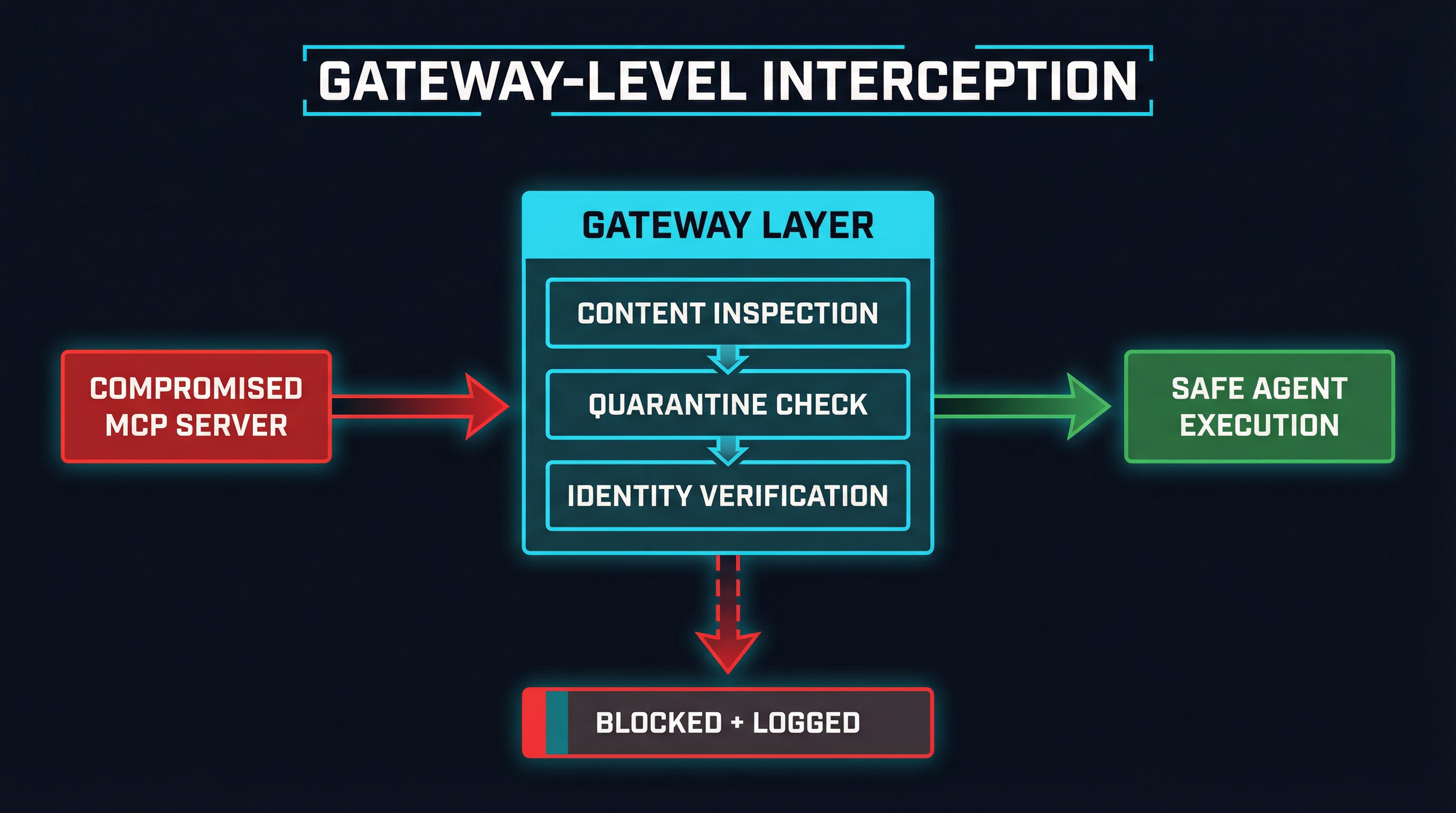
A gateway sits between agents and MCP servers, intercepting every protocol message in both directions. Unlike a network firewall that operates on packets and headers, an MCP gateway understands the protocol’s semantics — tool definitions, sampling requests, resource responses, context payloads. This allows it to apply security policies at the layer where the attacks actually occur.
Content Inspection at the Protocol Layer
Against ContextCrush-style attacks, a gateway performs runtime content inspection on every response from MCP servers before it reaches the agent. This means scanning tool descriptions, documentation payloads, and custom rules for instruction-like patterns — directives to read files, create network requests, delete data, or modify agent behavior.
This is not simple string matching. Effective content inspection uses pattern recognition tuned to the specific ways that context poisoning manifests: imperative instructions embedded in declarative documentation, encoded payloads designed to survive tokenization, and multi-step attack chains where individual components appear benign but combine into malicious behavior.
Projects like Sentrial implement policy-based content inspection, allowing teams to define rules about what content patterns are acceptable in MCP responses. MCPProxy combines content filtering with BM25-based tool discovery, reducing the number of tools exposed to the agent and thereby shrinking the attack surface for tool poisoning. mcp-vet takes an auditing approach, scanning MCP servers for known vulnerability patterns before they reach production.
Quarantine for Unknown and Changed Tools
The quarantine pattern treats MCP server connections the way endpoint security treats unknown executables: guilty until proven innocent. When a gateway encounters a new tool definition — or detects that an existing tool’s schema has changed — it holds the tool in quarantine rather than making it immediately available to the agent.
Quarantined tools are analyzed for known attack patterns, tested against policy rules, and compared against their registry metadata. Tools that pass review are released to the agent pool. Tools that fail are blocked and logged for manual review. This directly addresses both the ContextCrush scenario (where poisoned content was delivered through a new library registration) and OWASP MCP03 (Tool Poisoning), where rug pulls and schema poisoning modify tools after initial review.
Schema pinning, as implemented by SchemaPin, provides the cryptographic foundation for this. If a tool’s schema does not match its signed baseline, the gateway rejects it before the agent ever sees it.
Docker Isolation as Blast Radius Containment
Even with content inspection and quarantine, defense in depth requires assuming that some attacks will get through. Container isolation — running MCP servers in sandboxed Docker environments — limits the blast radius when they do.
An MCP server running in a Docker container with restricted filesystem access, no network egress to unauthorized endpoints, and resource limits cannot exfiltrate .env files from the host system, even if it successfully poisons the agent’s context. The attack payload executes, but the container boundary prevents it from reaching anything valuable.
This is the principle of least privilege applied at the infrastructure layer. The agent communicates with the MCP server through the gateway, the gateway mediates the connection, and the server itself runs in an environment where the most damaging attack outcomes are architecturally impossible.
The Identity Gap: The Missing Piece
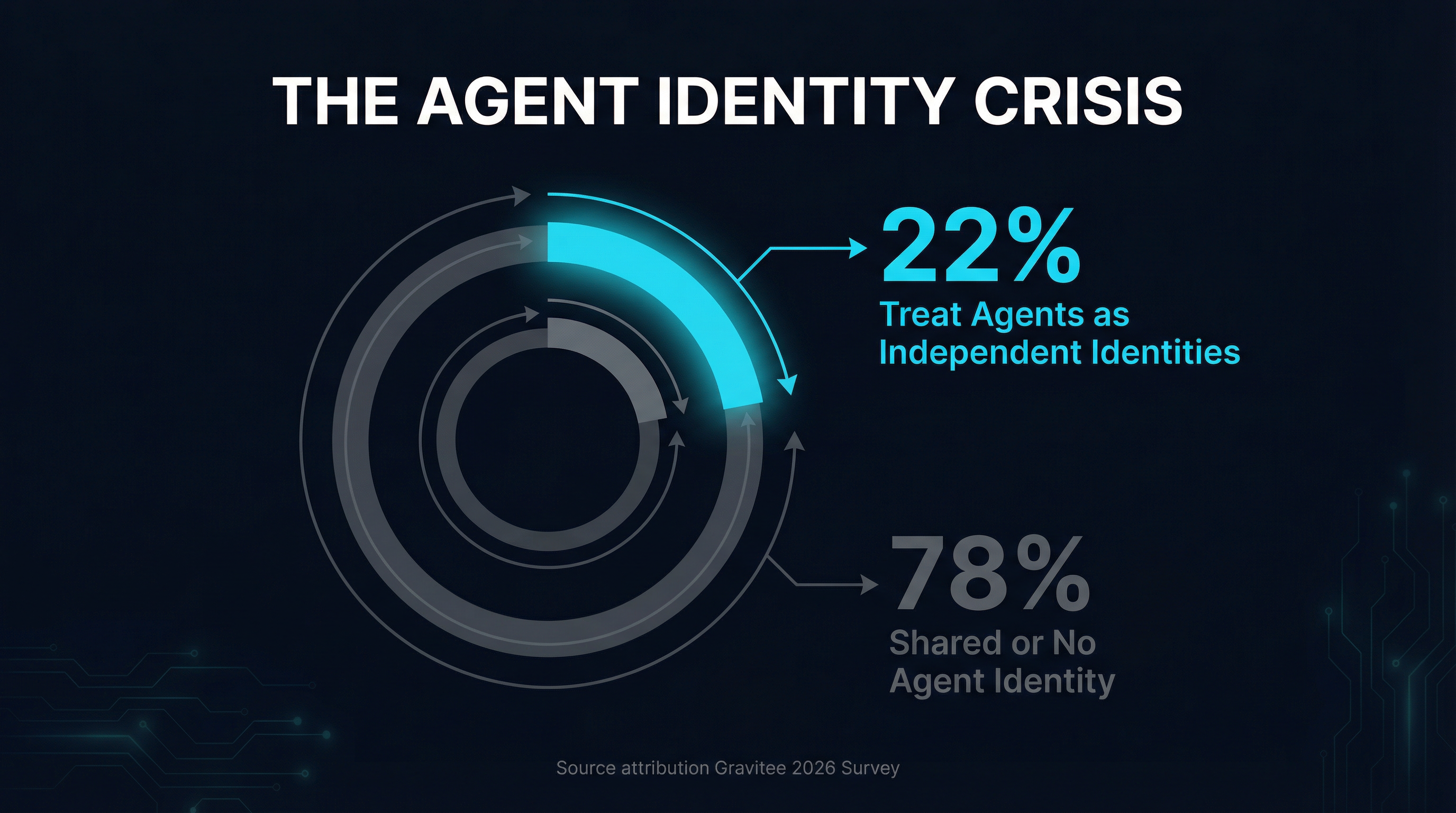
Gravitee’s 2026 State of AI Agent Security report contains a statistic that should alarm every security team: only 21.9% of organizations treat AI agents as independent, identity-bearing entities. The rest rely on shared credentials, hardcoded API keys, or no identity management at all.
This matters because gateway-level interception is only as strong as its identity model. A gateway that cannot distinguish between Agent A (authorized to access production databases) and Agent B (authorized to read public documentation) cannot enforce meaningful access policies. Every agent gets the same permissions, which means every compromised agent has the same blast radius.
The numbers get worse the deeper you look. 45.6% of organizations use shared API keys for agent-to-agent authentication. 27.2% rely on custom hardcoded authorization logic. Only 14.4% report full security approval for their entire agent fleet. And 88% of organizations reported confirmed or suspected AI agent security incidents in the last year.
Per-agent identity at the gateway layer is what transforms a gateway from a simple filter into a real security boundary. When each agent has its own identity, the gateway can enforce per-agent policies: which MCP servers this agent may connect to, which tools it may invoke, what data it may access, and what actions require human approval. Without this, gateway policies are one-size-fits-all, and a single compromised agent inherits the union of all agents’ permissions.
NIST’s draft guidance on agentic AI identity governance, expected mid-2026, is pushing the ecosystem in this direction. The OWASP MCP Top 10 dedicates two entries to it (MCP07 — Insufficient Authentication and Authorization, MCP01 — Token Mismanagement). The tooling is catching up, but adoption has not.
What Practitioners Should Do Today
The attacks are real. The defenses exist but require deliberate architectural choices. Here are three concrete steps that address the highest-risk scenarios.
1. Deploy a gateway between your agents and MCP servers. This is the single most impactful change. Stop allowing agents to connect directly to MCP servers over stdio or unauthenticated SSE. Route all MCP traffic through a gateway that can inspect content, enforce policies, and quarantine suspicious tools. Open-source options include mcpproxy-go, Sentrial, and MCP Context Forge by IBM. Commercial platforms like Gravitee and Kong are adding MCP-aware gateway capabilities. Pick one that fits your stack and deploy it this week.
2. Assign independent identities to every agent. Stop using shared API keys. Each agent should authenticate with its own credentials, scoped to only the MCP servers and tools it needs. This is not just a best practice — it is the prerequisite for meaningful access control. If your gateway cannot tell agents apart, it cannot enforce different policies for different agents. Use OAuth 2.1 with per-agent client credentials where possible. At minimum, use unique API keys with explicit scope restrictions.
3. Enable quarantine for new and changed tool schemas. Do not allow new MCP server tools to reach your agents without review. Configure your gateway to quarantine any tool definition it has not seen before, or any tool whose schema has changed since last verification. Use schema pinning (SchemaPin or hash-based verification) to detect drift. Review quarantined tools before releasing them. This single control would have prevented ContextCrush from reaching any agent behind the gateway.
The Window Is Closing
The MCP ecosystem is at a critical juncture. The protocol has achieved the adoption that makes it a high-value target — 97 million monthly SDK downloads, 8 million server downloads, integration into every major IDE and agent framework. The attacks demonstrated in Q1 2026 are not sophisticated nation-state operations. They are researcher-grade exploits that require modest effort and exploit fundamental trust assumptions in the protocol’s design.
The defenses — gateway interception, content inspection, quarantine, identity management, container isolation — are available today. They are not experimental. They are production-ready patterns implemented by multiple projects across the ecosystem. The gap is not in tooling. It is in deployment.
Every week that agents connect to MCP servers without gateway-level protection is a week where ContextCrush-style attacks, sampling hijacks, and credential exfiltration are possible with minimal attacker effort. The research is public. The exploit patterns are documented. The question is not whether these attacks will be attempted in production environments, but whether your infrastructure will catch them when they are.