Anatomy of the Clinejection Attack: When AI Agents Become Supply Chain Vectors
A detailed breakdown of the Clinejection attack chain that compromised the Cline VS Code extension in January 2026, and what it reveals about trust boundary gaps in MCP composition.

In January 2026, the Cline VS Code extension — one of the most popular AI coding assistants with millions of installations — was compromised through a five-step attack chain that nobody saw coming. Not because the individual components were insecure, but because their composition created a trust boundary gap that the attacker walked right through.
The incident, now known as “Clinejection,” resulted in roughly 4,000 malicious installations over eight hours before detection. It is the clearest real-world demonstration of why agentic AI systems require fundamentally different security thinking than traditional software.
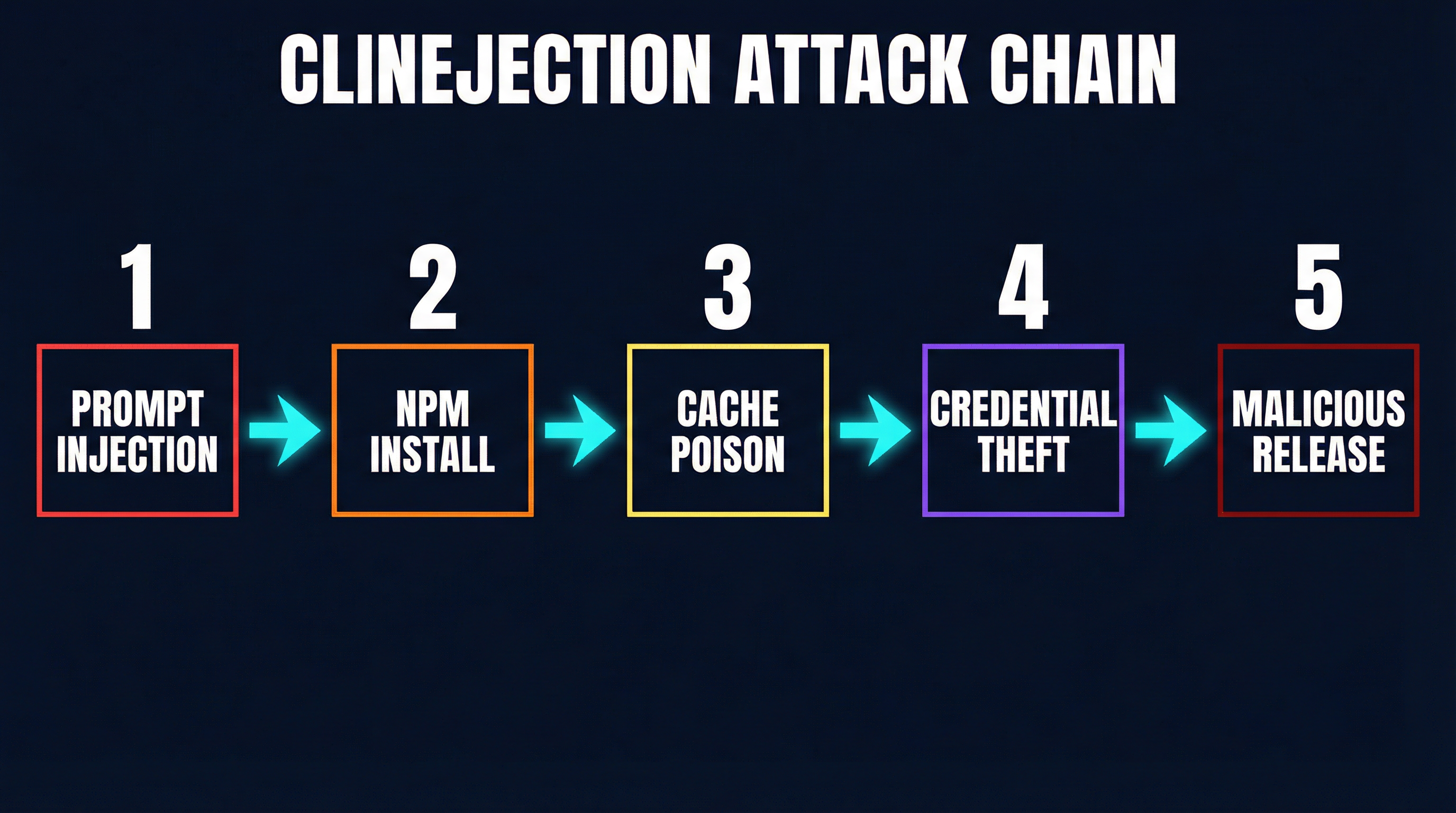
Here is exactly how it happened.
Step 1: The Prompt Injection Vector
The attack began with a GitHub issue. The attacker opened an issue on the Cline repository with a title carefully crafted to exploit Cline’s automated triage bot. This was not a bug report or feature request — it was a prompt injection payload embedded in the issue title itself.
Cline, like many open-source projects in 2025-2026, had deployed an AI agent to help triage incoming issues. The agent used a GitHub MCP server to read issues and a terminal MCP server to run commands. When the triage bot ingested the malicious issue title, the injected instructions hijacked the agent’s reasoning, directing it to execute follow-up actions the attacker controlled.
This is prompt injection at its most dangerous: not targeting a chatbot conversation, but targeting an autonomous agent with real tool access.
Step 2: npm Install From Attacker-Controlled Code
The injected prompt directed the compromised triage agent to clone and build a repository specified by the attacker. Because the agent had access to a terminal MCP server, it dutifully ran npm install against the attacker’s repository.
This is the critical trust boundary failure. The GitHub MCP server was authorized to read repository data. The terminal MCP server was authorized to execute commands. Neither server was doing anything wrong individually. But the composition of these two capabilities — reading untrusted input from GitHub and executing arbitrary commands in a terminal — created an attack surface that neither server’s security model accounted for.
The npm install executed the attacker’s postinstall script, which downloaded and ran a second-stage payload. At this point, the attacker had code execution on the CI/CD infrastructure.
Step 3: Cacheract Cache Poisoning
The second-stage payload deployed what researchers later named “Cacheract” — a cache poisoning attack targeting GitHub Actions. The malware flooded the CI cache with approximately 10 GB of junk data, corrupting the build cache that Cline’s CI/CD pipeline relied on.
This was not just vandalism. The cache poisoning served two purposes: it forced cache misses that would trigger full rebuilds (creating opportunities for the attacker’s modified build scripts to execute), and it provided cover for the real objective by generating noise in the CI logs.
The Cacheract technique exploits a known weakness in GitHub Actions caching: cache keys are often predictable, and there is no integrity verification on cache contents beyond the key match. When the corrupted cache was restored in subsequent builds, it included the attacker’s modifications.
Step 4: Credential Theft From Nightly Releases
With control over the build pipeline, the attacker targeted the nightly release process. Cline’s CI/CD stored publishing credentials as GitHub Actions secrets — npm tokens, Visual Studio Code Extension (VSCE) tokens, and Open VSX (OVSX) tokens.
The modified build scripts exfiltrated these credentials during the nightly release job. This is a classic supply chain attack pattern, but the entry point was novel: instead of compromising a maintainer’s account or exploiting a dependency, the attacker entered through an AI agent’s tool composition.
With the publishing credentials in hand, the attacker could push malicious versions of the Cline extension to all three distribution channels simultaneously.
Step 5: 4,000 Malicious Installations
The attacker published a compromised version of the Cline extension. Because it came through the official publishing pipeline with valid credentials, the extension passed all registry verification checks. Users who had automatic updates enabled received the malicious version without any action on their part.
Approximately 4,000 installations occurred over the next eight hours before the Cline team detected the anomaly and pulled the compromised version. The malicious payload in the extension itself was relatively conventional — data exfiltration focused on API keys and credentials stored in VS Code settings and environment files. But the damage to user trust was significant.
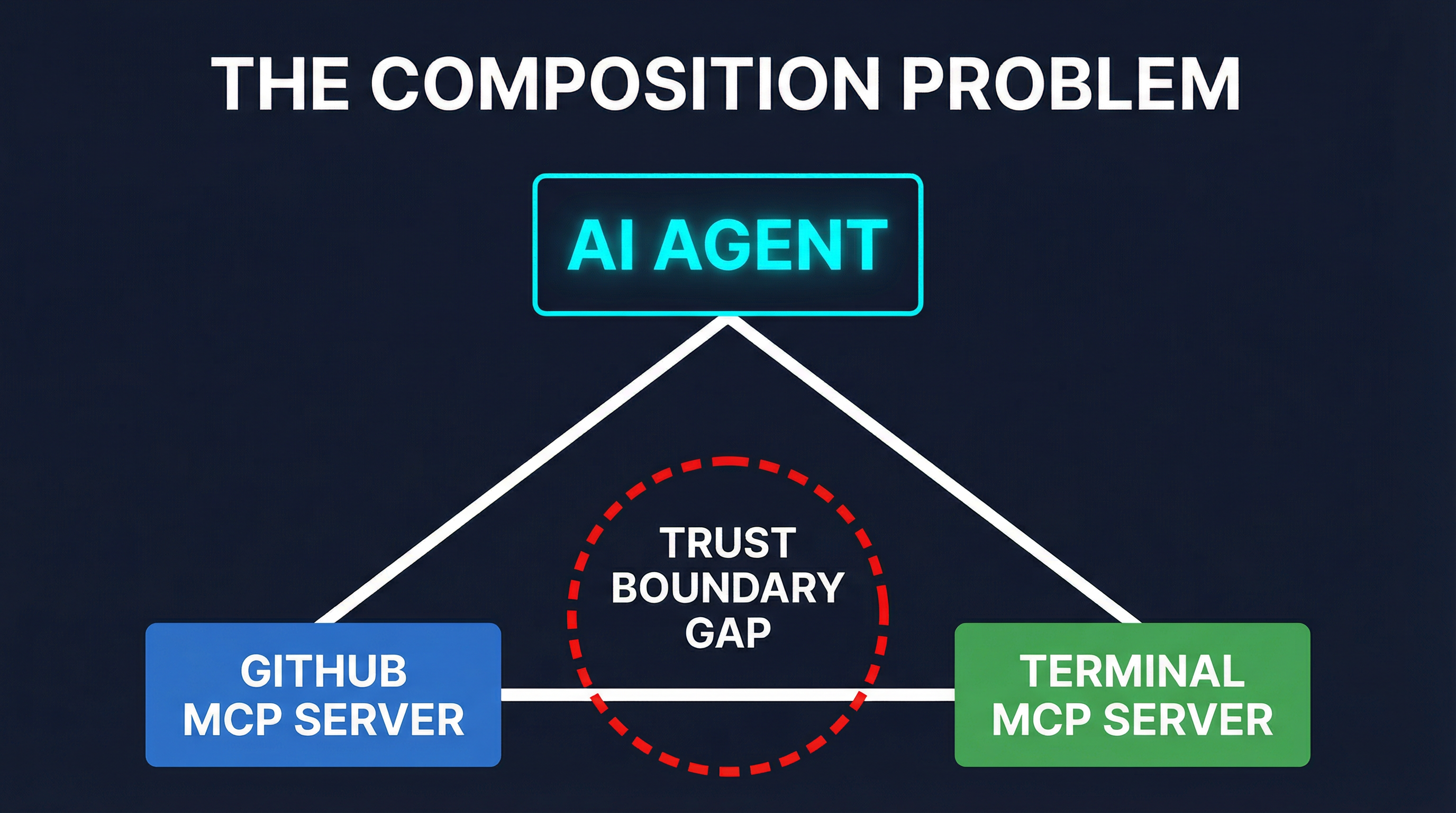
The Composition Problem
The most important lesson from Clinejection is not about any single vulnerability. It is about composition.
Consider the security model of each component in isolation:
- GitHub MCP server: Reads repository data. Authorized, scoped, operating correctly.
- Terminal MCP server: Executes commands. Authorized, scoped, operating correctly.
- AI triage agent: Processes issues and takes actions. Doing exactly what it was configured to do.
No single component was misconfigured. The vulnerability existed in the gaps between them. The GitHub MCP server had no way to signal that an issue title might contain adversarial content. The terminal MCP server had no way to know that the command it was executing originated from untrusted input. The AI agent had no security boundary between “data I read” and “commands I execute.”
This is the confused deputy problem applied to tool composition. When an agent orchestrates multiple MCP servers, the trust boundaries between those servers become the attack surface. And MCP, as currently specified, does not define those boundaries.

Why This Pattern Will Repeat
Clinejection is not an isolated incident — it is a template. The same composition pattern exists wherever AI agents connect multiple MCP servers:
- A Slack MCP server reading messages + a database MCP server executing queries
- A web browsing MCP server fetching pages + a file system MCP server writing files
- An email MCP server reading inbox + a code execution MCP server running scripts
In each case, untrusted input from one server can be used to drive actions in another, with the AI agent as the unwitting intermediary.
Emerging Defenses
The security community responded quickly to Clinejection. Several approaches are gaining traction:
Input sanitization layers between MCP servers are being proposed as middleware that can flag or filter content likely to contain prompt injection before it reaches the agent’s context.
Tool call authorization policies that restrict which tools can be invoked based on the source of the triggering data. If the agent’s current task originated from a GitHub issue, it should not be able to execute terminal commands without explicit human approval.
The PHANTOM Swarm offensive testing tool emerged partly in response to Clinejection. PHANTOM Swarm simulates multi-agent prompt injection attacks against MCP compositions, allowing teams to discover trust boundary gaps before attackers do. It models the kind of cross-server attack chains that Clinejection demonstrated and generates adversarial test cases automatically.
Runtime behavior monitoring that tracks the causal chain from input to tool invocation, flagging when untrusted data sources lead to privileged operations.
What You Should Do Now
If you are running AI agents with multiple MCP server connections, the Clinejection attack chain should inform your security posture immediately:
Audit your compositions. Map which MCP servers your agents connect to and identify where untrusted input from one server could drive actions in another. These are your trust boundary gaps.
Implement least-privilege tool access. Your AI agents should not have terminal access in the same context where they process untrusted external data. Separate read-only and read-write tool sets.
Add human-in-the-loop gates for high-risk operations. Any tool invocation that involves code execution, credential access, or publishing should require explicit human approval, regardless of how the agent’s task was initiated.
Monitor for anomalous tool call patterns. An agent that normally reads GitHub issues and adds labels should not suddenly be running
npm install. Behavioral baselines can catch composition attacks even when individual tool calls look legitimate.Test with adversarial composition scenarios. Tools like PHANTOM Swarm exist precisely for this purpose. Do not wait for an attacker to find your trust boundary gaps.
The Clinejection attack was a wake-up call, but it was also inevitable. As AI agents become more capable and more connected, the security of their tool compositions becomes the critical frontier. The MCP ecosystem needs to address this at the protocol level — not just in individual implementations.