Why Google Dropped MCP: Context Explosion and the Tool Discovery Problem
Google quietly removed MCP from its Workspace CLI after tool definitions ballooned context windows to 100K tokens. The tool discovery problem is MCP's biggest scaling barrier.

In early 2026, Google quietly deleted 1,151 lines of MCP integration code from its Workspace CLI. No announcement, no deprecation notice — just a commit that ripped out the entire MCP subsystem. The dev.to community noticed before Google’s own documentation was updated.
The reason was not a security incident or a strategic pivot. It was a scaling problem so fundamental that it threatens MCP adoption far beyond Google: context explosion from tool definitions.
The Problem: Death by Tool Description
When an AI agent connects to an MCP server, it receives tool definitions — names, descriptions, parameter schemas, and usage examples. These definitions are injected into the agent’s context window so the LLM can understand what tools are available and how to use them.
A single well-documented MCP tool might consume 200-500 tokens. A server with 10 tools generates 2,000-5,000 tokens of context. This is manageable. The problem starts when you connect multiple servers.
Google’s Workspace CLI integrated with MCP to provide access to Gmail, Calendar, Drive, Docs, Sheets, and other Workspace APIs. Each service exposed multiple tools — search, read, create, update, delete operations across dozens of resource types. The total tool definition payload reached 40,000-100,000 tokens before the agent processed a single user message.
For context, that is roughly the length of a short novel consumed just by tool descriptions. And this was not an extreme case — it was a straightforward enterprise integration connecting one product suite through MCP.

Why Oversized Context Windows Break Things
The naive response to context explosion is “just use a bigger context window.” Modern LLMs support 128K, 200K, or even 1M token contexts. Why not just load everything?
Three reasons, each sufficient on its own:
Reasoning quality degrades with context size. This is well-documented in the “lost in the middle” literature. LLMs pay less attention to information in the middle of long contexts. When 80% of your context is tool definitions, the actual user query and conversation history are competing with thousands of tool descriptions for the model’s attention. Tool selection accuracy drops measurably as the number of available tools increases.
Prompt injection surface area grows linearly. Every tool description is an opportunity for injection. A malicious MCP server can embed instructions in tool descriptions that manipulate the agent’s behavior. With 500 tools in context, the attack surface is 500 times larger than with a single tool. The agent cannot distinguish between legitimate tool descriptions and adversarial ones — they all look the same in the context.
Cost and latency scale with context. Token-based pricing means that sending 100K tokens of tool definitions on every request is expensive. Latency increases with context size, especially for the first token. Enterprise deployments serving thousands of users saw their inference costs dominated by static tool definitions rather than actual productive work.
Google’s engineers calculated that MCP tool definitions were consuming 60-80% of the available context in many Workspace CLI interactions. The remaining context was insufficient for multi-turn conversations with complex document operations. The integration was technically functional but practically unusable at scale.
The AnythingMCP Pattern Makes It Worse
The context explosion problem is accelerating because of tools like AnythingMCP that auto-convert existing APIs into MCP tool definitions. AnythingMCP can take REST, SOAP, or GraphQL API specifications and automatically generate corresponding MCP tools — complete with descriptions, parameter schemas, and validation.
One documented deployment generated 82 MCP tools from 15 backend systems. This is exactly the kind of integration that enterprise teams want: connect all your internal APIs to your AI agent through a single protocol. But 82 tools at 300-500 tokens each means 25,000-40,000 tokens of tool definitions before the agent does anything useful.
The AnythingMCP pattern reveals the fundamental tension in MCP’s design. The protocol was built to make tool integration easy, and it succeeded — so well that realistic enterprise deployments produce more tool definitions than agents can effectively process.
BM25 Pre-Filtering: A Practical Solution
The most effective approach to context explosion right now is pre-filtering tool definitions before they reach the LLM. Instead of loading all available tools into context, a retrieval layer selects only the tools relevant to the current query.
BM25 — a ranking algorithm from the information retrieval community dating back to the 1990s — turns out to be remarkably effective for this. BM25 scores documents (in this case, tool definitions) against a query using term frequency and inverse document frequency, without requiring any neural network inference.
The workflow looks like this:
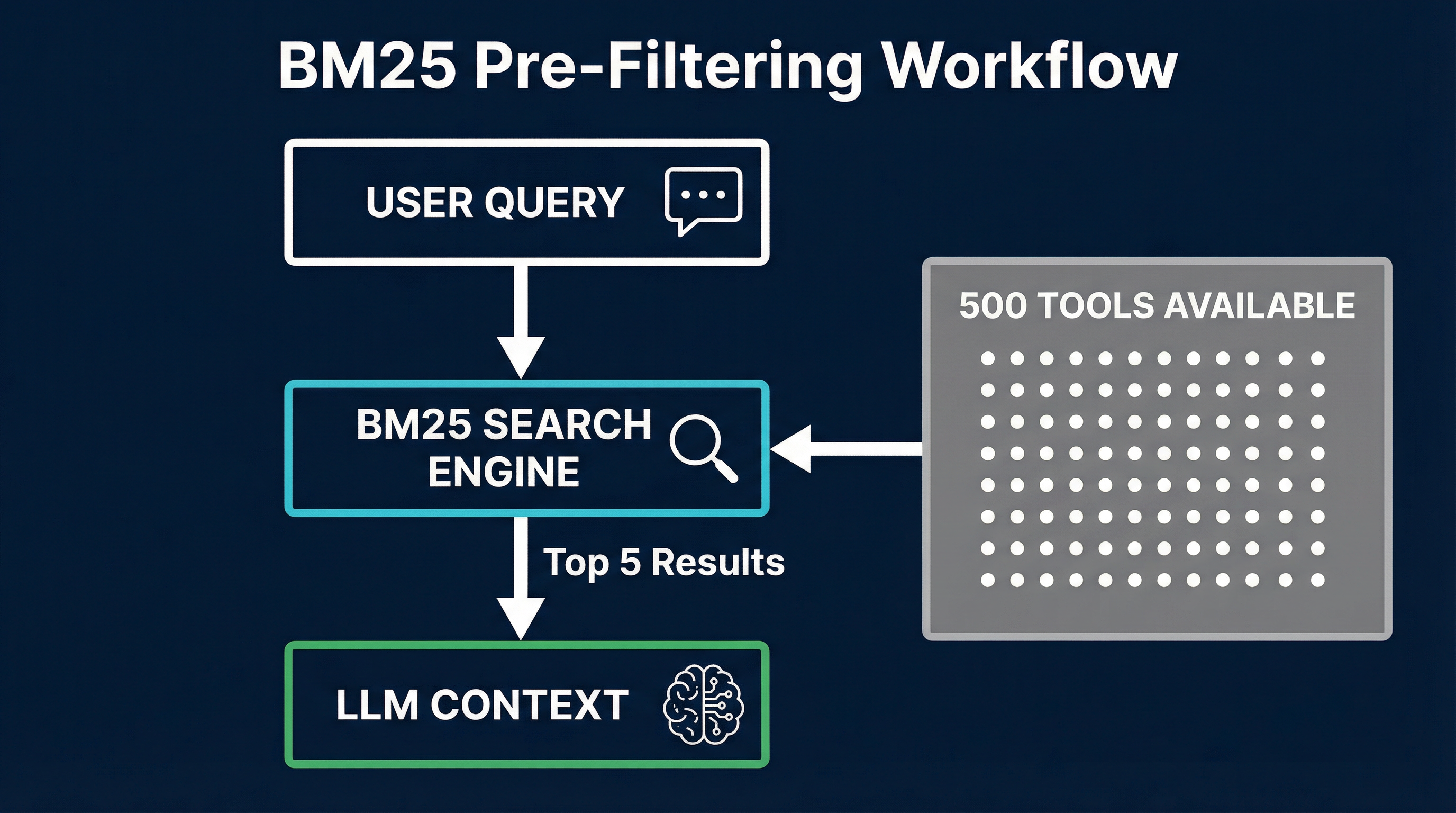
User query: "Schedule a meeting with the design team next Tuesday"
1. BM25 scores all available tool definitions against the query
2. Top 3-5 tools are selected (e.g., calendar_create_event,
contacts_search, calendar_check_availability)
3. Only selected tool definitions are injected into the LLM context
4. LLM reasons over 1,500 tokens of tools instead of 50,000This reduces cold-start context from 50,000+ tokens to the 3-5 most relevant tools per query. The BM25 scoring step adds negligible latency — typically under 10 milliseconds for hundreds of tools — because it requires no GPU inference.
The key insight is that tool selection does not need to be perfect. It needs to be good enough to include the relevant tools while excluding the irrelevant majority. BM25’s precision at this task is surprisingly high because tool descriptions contain distinctive terminology that correlates well with user intent.
The RAG-MCP Paper: Quantifying the Improvement
A research paper from May 2025 (arXiv:2505.03275) formalized the retrieval-first approach to MCP tool selection as “RAG-MCP” — retrieval-augmented generation applied to MCP tool routing. The results were striking.
In their evaluation, standard MCP tool routing (loading all tools into context) achieved 13.6% accuracy on a benchmark of multi-tool tasks. RAG-MCP, which used a retrieval layer to select relevant tools before presenting them to the LLM, achieved 43.1% accuracy on the same benchmark.
That is a 3x improvement in tool selection accuracy simply by not overwhelming the LLM with irrelevant tool definitions. The paper also showed that the improvement increased with the total number of available tools — exactly the scenario that matters for enterprise deployments.
The RAG-MCP approach used embedding-based retrieval rather than BM25, which provides better semantic matching but requires a vector database and embedding model. In practice, hybrid approaches combining BM25 for initial filtering with embedding-based reranking offer the best tradeoff between quality and infrastructure complexity.
What Google Could Have Done
Google’s decision to remove MCP was pragmatic — the integration was not working well enough for their quality bar. But context explosion is solvable without abandoning MCP entirely.
A pre-filtering layer between the MCP servers and the agent context would have reduced tool definitions from 100K tokens to under 5K per query. The Workspace API structure is actually well-suited for retrieval-based routing because each service has distinctive terminology: “email” queries route to Gmail tools, “spreadsheet” queries route to Sheets tools, and so on.
The fact that Google chose removal over optimization suggests either that the MCP integration was not strategically important enough to justify the engineering investment, or that Google’s internal tooling team decided to build their own non-MCP tool protocol. Given Google’s history of preferring proprietary solutions, the latter is plausible.
The Broader Ecosystem Response
The context explosion problem is driving architectural changes across the MCP ecosystem:
Lazy tool loading is being adopted by several MCP client libraries. Instead of fetching all tool definitions at connection time, clients request tool definitions on-demand based on routing hints from the agent’s current task.
Tool definition compression reduces the token footprint of each tool. Short descriptions, minimal examples, and schema-only definitions (without natural language explanations) can reduce per-tool tokens by 60-70%. The tradeoff is that the LLM may be less accurate in using tools it has less context about.
Hierarchical tool registries organize tools into categories and let the agent navigate the hierarchy rather than loading a flat list. The agent first selects a category (“calendar operations”), then loads only the tools within that category.
Server-side pre-filtering, where the MCP server itself accepts a query and returns only relevant tools from its catalog, pushes the filtering logic to the tool provider. This is the approach that MCP proxy servers are well-positioned to implement.

What You Should Do Now
If you are building or deploying MCP integrations with more than 20 tools, context explosion is likely already affecting your quality:
Measure your tool context overhead. Count the tokens consumed by tool definitions in a typical request. If tool definitions exceed 30% of your total context, you have a problem.
Implement pre-filtering. BM25 is the simplest starting point — it requires no ML infrastructure, runs in milliseconds, and provides substantial context reduction. Libraries like
rank_bm25in Python make this a dozen lines of code.Profile tool usage patterns. Most agents use a small fraction of available tools for any given query. Track which tools are actually invoked and use that data to optimize your routing.
Consider an MCP proxy with built-in discovery. Proxy servers that implement BM25 or embedding-based pre-filtering at the routing layer solve context explosion transparently, without requiring changes to your agent or MCP servers.
Do not load all tools into context. This is the single most actionable takeaway. If you are connecting more than a handful of MCP servers, a flat tool list in your agent’s context is a scaling dead end. Retrieval-first routing is not optional at enterprise scale — it is a requirement.
Google learned this the hard way. You do not have to.